
谷歌用AI从嘈杂环境中提取独立音轨:或存隐私担忧
北京时间4月16日早间消息,谷歌研究人员开发了一种深度学习系统,可以帮助电脑在嘈杂环境中更好地识别和区分一个人的声音。本周在谷歌研究博客中发布的文章显示,该公司的一个内部团队试图让人工智能(AI)像人类的大脑一样,可以主动关注一个声源,同时过滤其他声源——就像你在聚会上跟朋友对话时的做法。
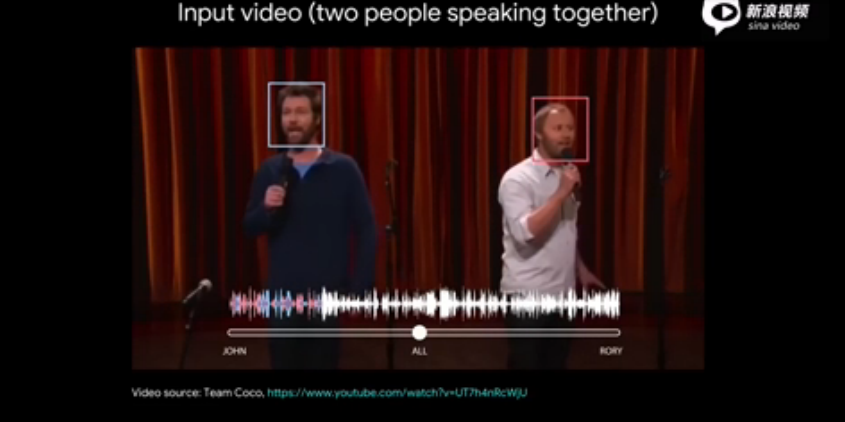
谷歌的方法使用了一个视听模型,使之可以集中精力区分一段视频中的声音。该公司还发布了多段YouTube视频,演示这项技术的实际效果。
谷歌表示,这项技术可以适用于单音轨视频,而且可以通过算法分离出视频中不同人的音频内容,也可以让用户手动选取视频中的人脸,专门收听此人的声音。
谷歌表示,视觉元素是关键,因为这项技术会关注一个人的嘴唇运动,从而更好地判断某个时点应该关注哪段声音,并为一段较长的视频创造更精确的独立音轨。
谷歌研究人员通过收集10万段YouTube“演讲视频”开发了这个模型,总共提取了大约2000小时的内容,然后将这些音轨混合后,添加上人工背景噪音。
谷歌之后训练该技术通过观察每一格视频中的人脸和视频音轨的频谱图,把混合后的音频进行分割。这套系统可以区分哪个声源在特定时间内属于哪张脸,并为每个人制作一段独立的音轨。
谷歌认为,隐藏式字幕系统会成为该系统的一大应用领域,他们还在设想更广泛的应用方向,而且还在探索更多的机会,希望将其整合到各种谷歌产品中。例如,如果把它加入到Google Home智能音箱中,便可区分出不同用户发出的指令。
不过,这个模型需要配合视频才能更好地发挥作用,所以可能更适合亚马逊Echo Show。谷歌今年早些时候面向Echo Show这样的智能显示器开放了谷歌助手,但该公司本身尚未推出这样的产品。
但这项技术可能也会引发隐私担忧。虽然该技术的实际效果远没有视频演示得那么好,但经过一些细微调整,的确有可能成为强大的监听和监视工具。(思远)
(文章来源:新浪科技)
转载声明:本站文章若无特别说明,皆为本站原创或首译,转载请注明来自:电音哦(www.chinamidi.cn),谢谢!^^






谷歌用AI从嘈杂环境中提取独立音轨:或存隐私担忧:等您坐沙发呢!